Dia
综合介绍
Dia是由Nari Labs开发的一款拥有16亿参数的文本转语音(TTS)模型。 它主要用于从文本脚本直接生成听起来非常真实的对话音频。和传统的TTS模型不同,Dia不仅仅是朗读文本,它能够模拟多个人之间的对话,并且可以加入笑声、咳嗽、清嗓子等非语言声音,让对话听起来更自然。 用户可以通过提供一小段音频样本来克隆声音,从而控制输出音频的音色和情感风格。 Dia是一个开源项目,模型和代码都可以在GitHub和Hugging Face上找到,目前仅支持英语。 该项目由两位大学生在没有外部资金的情况下创建,利用了Google和Hugging Face提供的研究资源,被看作是开源AI领域挑战商业模型的一个例子。
功能列表
- 对话生成: 使用
[S1]和[S2]等说话人标签,在一段音频中生成两个或多个人之间的对话。 - 非语言声音生成: 支持在文本中加入
(laughs)(笑声),(coughs)(咳嗽),(sighs)(叹气)等超过20种标签,以生成对应的非语言声音,提升真实感。 - 零样本语音克隆: 只需提供5到10秒的目标语音片段及其文本转录,模型就能模仿该语音的音色、风格和情感来生成新的音频内容。
- 开源和可访问性: 模型权重和推理代码在GitHub上根据Apache 2.0许可证完全开源,并已集成到Hugging Face Transformers库中,方便开发者使用。
- 多种使用方式: 提供Gradio Web用户界面、命令行工具(CLI)以及Python脚本等多种方式来运行模型。
- 声音一致性控制: 用户可以通过提供音频提示或固定随机种子(seed)来确保在多次生成中说话人的声音保持一致。
使用帮助
Dia模型提供了多种使用方式,包括直接使用Hugging Face Transformers库、通过克隆GitHub仓库运行,或使用Gradio用户界面进行交互。以下是详细的操作指南。
硬件要求
在开始之前,请确保你的设备满足以下条件:
- GPU: 必须有支持CUDA 12.6及以上版本的NVIDIA显卡。
- 显存: 根据使用的精度不同,需要约4.4GB至7.9GB的显存。
- 软件: 需要安装Python和PyTorch 2.0+。目前模型暂不支持CPU运行。
方式一:通过Hugging Face Transformers快速上手(推荐)
这是最简单直接的使用方式,推荐给希望快速集成的开发者。
- 安装Transformers主分支你需要安装Hugging Face Transformers库的最新开发版本。打开终端并执行以下命令:
pip install git+https://github.com/huggingface/transformers.git或者,如果你使用
uv包管理器:uv pip install git+https://github.com/huggingface/transformers.git - 编写Python脚本运行创建一个Python文件(例如
run_dia.py),将以下代码复制进去。这段代码将加载模型和处理器,根据输入文本生成音频,并保存为example.mp3文件。from transformers import AutoProcessor, DiaForConditionalGeneration import torch # 确定计算设备,优先使用CUDA torch_device = "cuda" if torch.cuda.is_available() else "cpu" # 模型检查点 model_checkpoint = "nari-labs/Dia-1.6B-0626" # 输入文本,使用[S1]和[S2]区分不同说话人 text = [ "[S1] Dia is an open weights text to dialogue model. " "[S2] You get full control over scripts and voices. " "[S1] Wow. Amazing. (laughs) " "[S2] Try it now on Git hub or Hugging Face." ] # 加载处理器和模型 processor = AutoProcessor.from_pretrained(model_checkpoint) model = DiaForConditionalGeneration.from_pretrained(model_checkpoint).to(torch_device) # 处理输入文本 inputs = processor(text=text, padding=True, return_tensors="pt").to(torch_device) # 生成音频 # guidance_scale, temperature, top_p, top_k 是控制生成质量和多样性的参数 outputs = model.generate( **inputs, max_new_tokens=3072, guidance_scale=3.0, temperature=1.8, top_p=0.90, top_k=45 ) # 解码并保存音频 decoded_outputs = processor.batch_decode(outputs) processor.save_audio(decoded_outputs, "example.mp3") print("音频已生成并保存为 example.mp3") - 执行脚本在终端中运行该脚本:
python run_dia.py执行完毕后,你会在当前目录下找到一个名为
example.mp3的音频文件。
方式二:克隆GitHub仓库并运行
这种方式让你能接触到项目的完整代码,包括示例和命令行工具。
- 克隆仓库
git clone https://github.com/nari-labs/dia.git cd dia - 安装依赖使用
pip安装项目所需的依赖库:pip install -e . - 运行示例仓库的
example目录下包含了一些预设好的脚本,例如:- 简单生成:
python example/simple.py - 语音克隆:语音克隆是Dia的特色功能。你需要准备一段5到10秒的
.mp3或.wav格式的音频作为声音样本,并提供该音频的精确文本转录。查看并修改example/voice_clone.py文件,将你的音频路径、转录文本和希望生成的新文本填入。# 在 example/voice_clone.py 中修改 prompt_text = "[S1] 这里是你的音频样本的转录文本。" # 必须和音频内容完全对应 text_to_generate = "[S1] 这是你想要用克隆声音生成的新内容。" audio_prompt_path = "path/to/your/audio.mp3" # 你的音频文件路径然后运行脚本:
python example/voice_clone.py
- 简单生成:
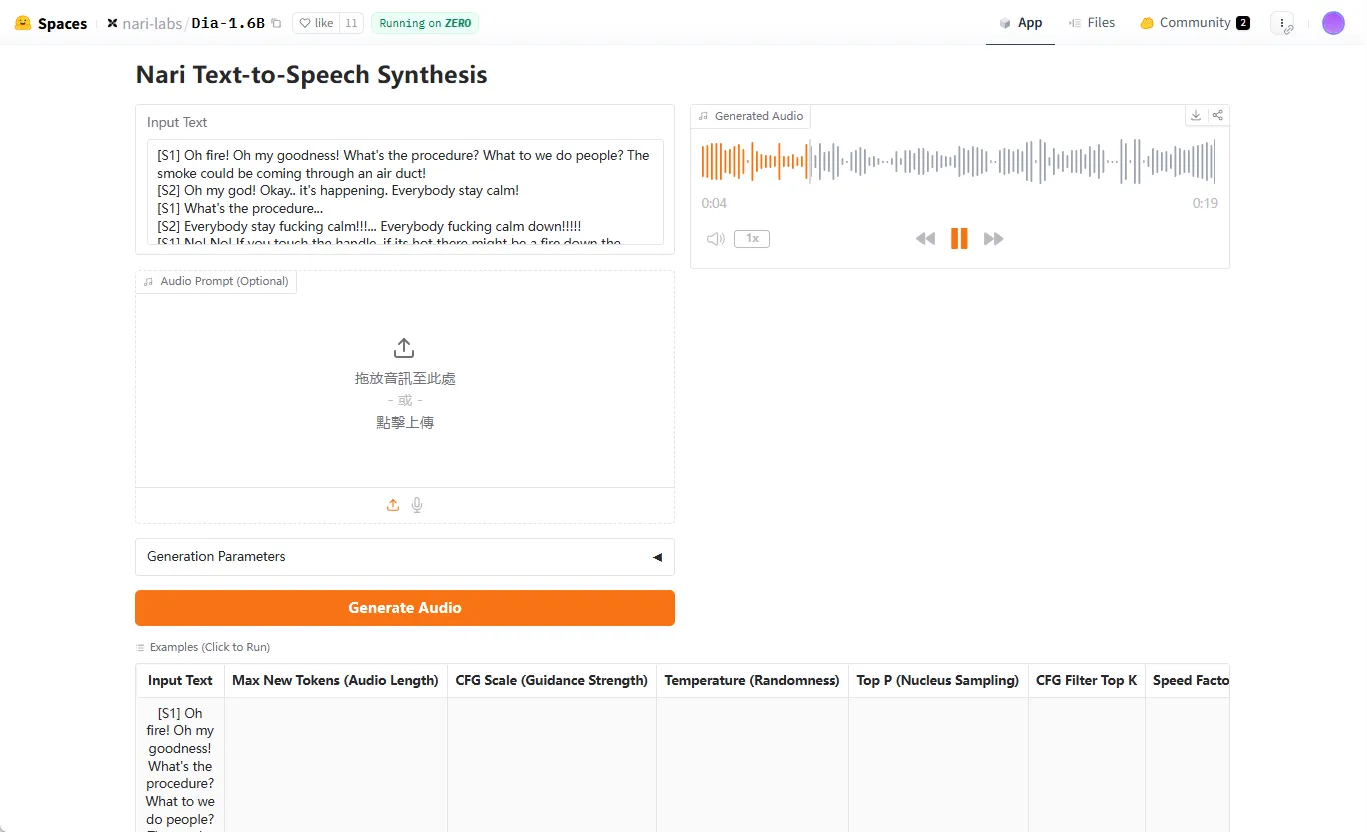
方式三:使用Gradio Web用户界面
这是一种对非开发者用户最友好的方式,提供了一个可视化的操作界面。
- 确保依赖已安装按照方式二的步骤克隆仓库并安装依赖。
- 启动Gradio应用在
dia项目根目录下,运行以下命令:python app.py或者使用
uv:uv run app.py - 在浏览器中打开命令执行后,终端会显示一个本地网址(通常是
http://127.0.0.1:7860)。在浏览器中打开该地址,即可看到操作界面。- 输入文本: 在“Script”文本框中输入你的对话脚本。
- 语音克隆: 如果需要克隆声音,上传你的音频样本,并在脚本的开头部分准确填写该音频的转录。
- 生成: 点击“Generate”按钮,等待片刻即可在界面上播放或下载生成的音频。
应用场景
- 播客和有声书制作创作者可以利用Dia为播客或有声书生成多角色的对话音频,不再需要多人录音。通过语音克隆功能,甚至可以用自己的声音扮演多个不同角色,只需提供一小段声音样本即可。
- 游戏开发游戏开发者可以用Dia为非玩家角色(NPC)快速生成大量对话。通过在脚本中加入笑声、叹气等非语言提示,可以赋予NPC更生动和真实的情感,增强游戏的沉浸感。
- 内容创作和社交媒体社交媒体上的内容创作者可以使用Dia来制作有趣的对话视频或音频剪辑。例如,可以快速生成两个虚拟角色之间的辩论或访谈,并分享到视频平台,丰富内容形式。
- 原型设计和教育产品设计师在开发需要语音交互的应用时,可以使用Dia快速生成原型所需的语音反馈。在教育领域,它可以用来创建语言学习材料,模拟真实对话场景,帮助学生练习听力。
QA
- Dia支持中文吗?目前Dia模型仅支持英语的文本转语音生成。
- 我没有GPU,可以在CPU上运行Dia吗?不行。当前版本的Dia模型必须在支持CUDA的GPU上运行,官方计划在未来加入对CPU的支持。
- 生成的每个说话人的声音都是随机的吗?如何保持声音一致?是的,如果不进行额外设置,每次生成时模型都会产生随机的声音。 要想保持声音一致,有两种方法:一是在生成时提供一个固定的音频样本(即语音克隆),二是通过在代码中设置固定的
seed(随机种子)值。 - 使用语音克隆功能时有什么技巧?为了达到最好的克隆效果,官方建议提供5到10秒时长的音频样本。 同时,必须在生成脚本的开头部分提供与这段音频内容完全一致的文本转录,并正确使用
[S1]或[S2]标签。